
Publications
Selected work on multimodal understanding, multimodal foundation models, and video understanding — spanning VLMs, multimodal LLMs, and vision–language–action (VLA) models. For the complete list, see my Google Scholar.
Foundation Models & Technical Reports

PI · 2026
π0.7: A Steerable Model with Emergent Capabilities
Generalist robot foundation model with emergent compositional capabilities across dexterous manipulation tasks and robot platforms.
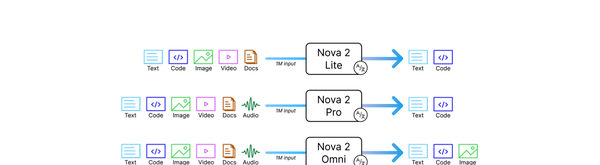
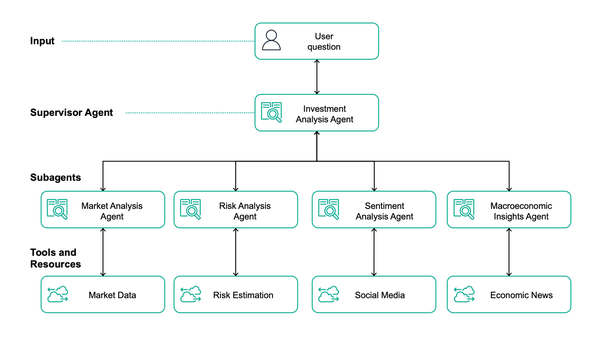
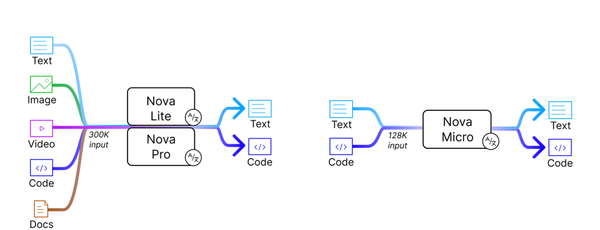
Amazon · 2025
Amazon Nova Premier
Most capable Nova model for complex tasks and a teacher for model distillation.
Selected Publications
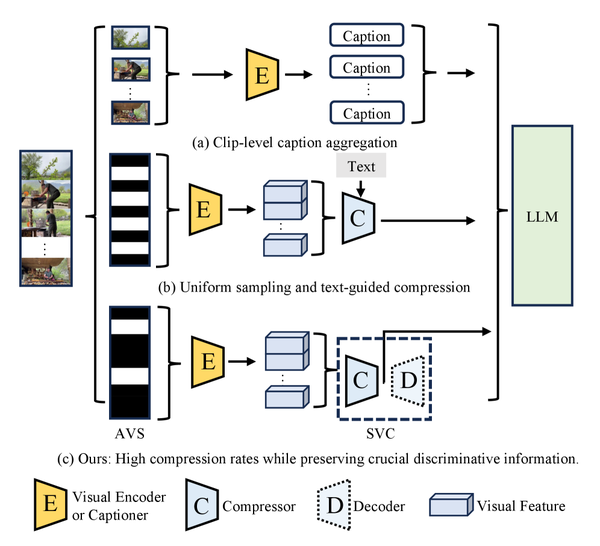
WACV 2026
Learning Compact Video Representations for Efficient Long-form Video Understanding in LMMs
Compact representations for efficient long-form video understanding in large multimodal models.
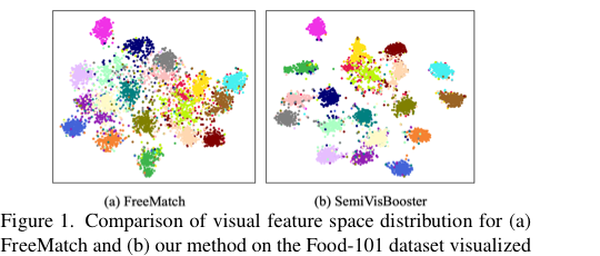
ICCV 2025
SemiVisBooster: Semi-Supervised Learning via Pseudo-Label Semantic Guidance
Text-guided semi-supervised learning for fine-grained classification.
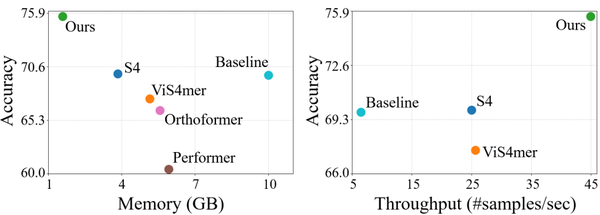
NeurIPS 2024
Video Token Merging for Long Video Understanding
Learnable token merging for long-form video transformers — large memory and throughput wins.

ECCV 2024
Text-Guided Video Masked Autoencoder
Video MAE with text-guided masking and joint video–text contrastive learning.
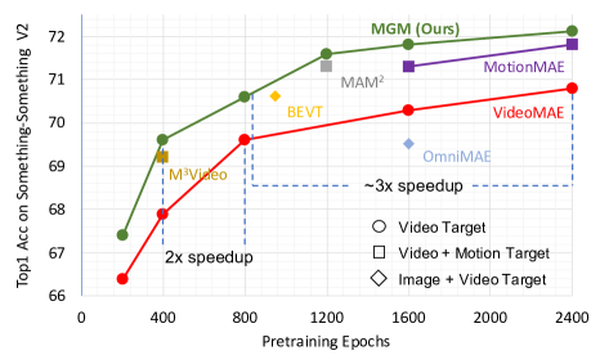
ICCV 2023
Motion-Guided Masking for Spatiotemporal Representation Learning
Motion-aware masking for video self-supervised learning.
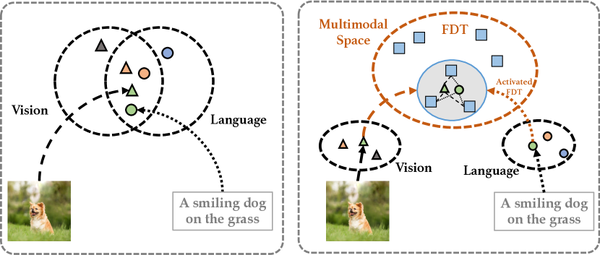
CVPR 2023
Revisiting Multimodal Representation in Contrastive Learning
CLIP-style pretraining with finite discrete tokens to close vision–language granularity gaps.
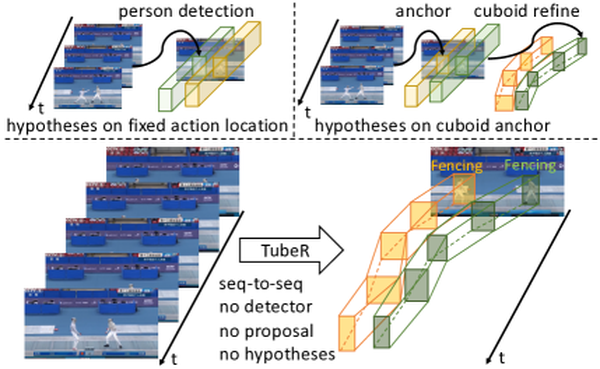
CVPR 2022Oral
TubeR: Tubelet Transformer for Video Action Detection
End-to-end transformer for spatiotemporal action detection — no detector, no proposals.
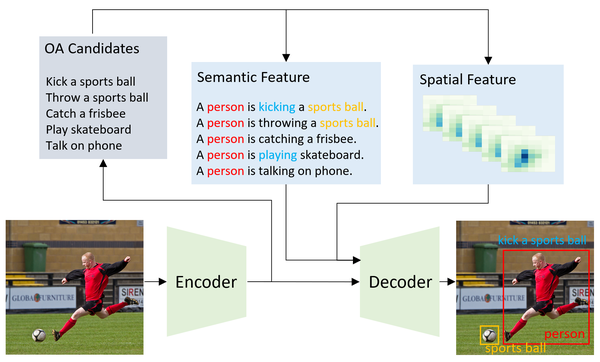
CVPR 2022Oral
SSRT: Semantic & Spatial Refined Transformer for HOI Detection
What to look at and where — refined transformer for human–object interaction detection.
CVPR 2022Oral
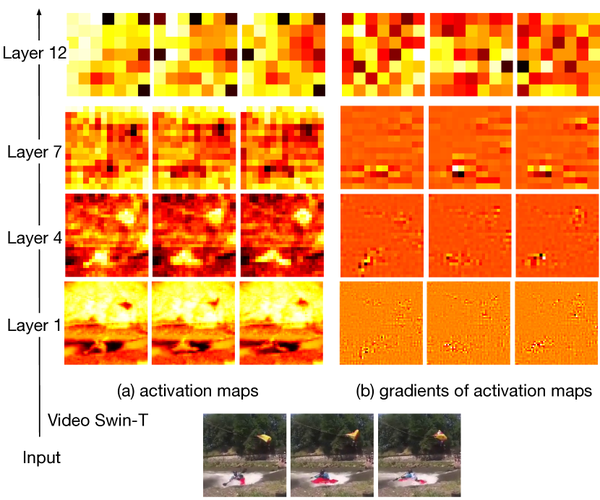
Stochastic Backpropagation for Video Models
Memory-efficient video training via stochastic backprop / temporal gradient dropout.
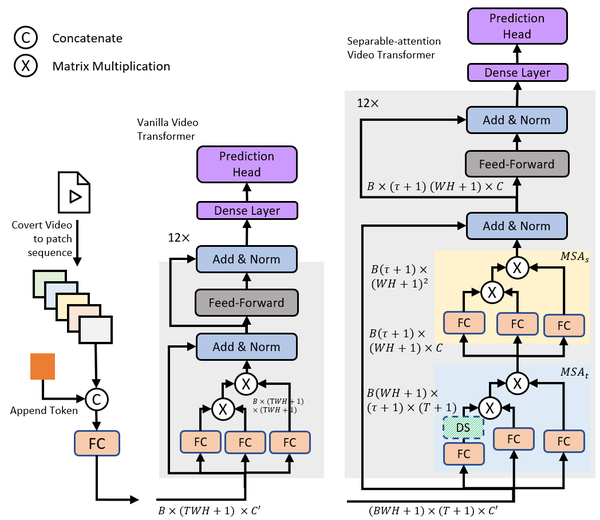
ICCV 2021
VidTr: Video Transformer Without Convolutions
Convolution-free video transformer architecture.
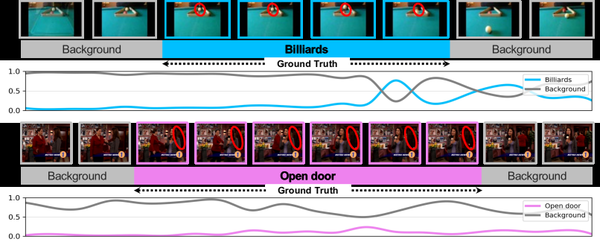
NeurIPS 2021Spotlight
LSTR: Long Short-Term Transformer for Online Action Detection
Long/short-term temporal modeling for streaming action detection.

ECCV 2020Spotlight
Directional Temporal Modeling for Action Recognition
Making convolutions temporal-aware.
Patents
- US 2026US12526485B1 — Content-aware graphical subtitles.
- US 2025US12387097B2 — Efficient video processing via temporal progressive learning.
- US 2022US11423265B1 — Content moderation using object detection and image classification.
Open Source
- GluonCV Core contributor; deep-learning toolkit for computer vision with 5.9K+ GitHub stars. PyPI
- GluonMM Core contributor; a multimodal modeling toolkit. GitHub
- TubeR Official implementation of the Tubelet Transformer for video action detection. Paper
- STORM-Bench Benchmark and code for MLLM-based referring multi-object tracking. GitHub